As it happens, we still use CVS in our operating system project (there are reasons for doing this, but migration to git would indeed make sense)
-
As it happens, we still use CVS in our operating system project (there are reasons for doing this, but migration to git would indeed make sense).
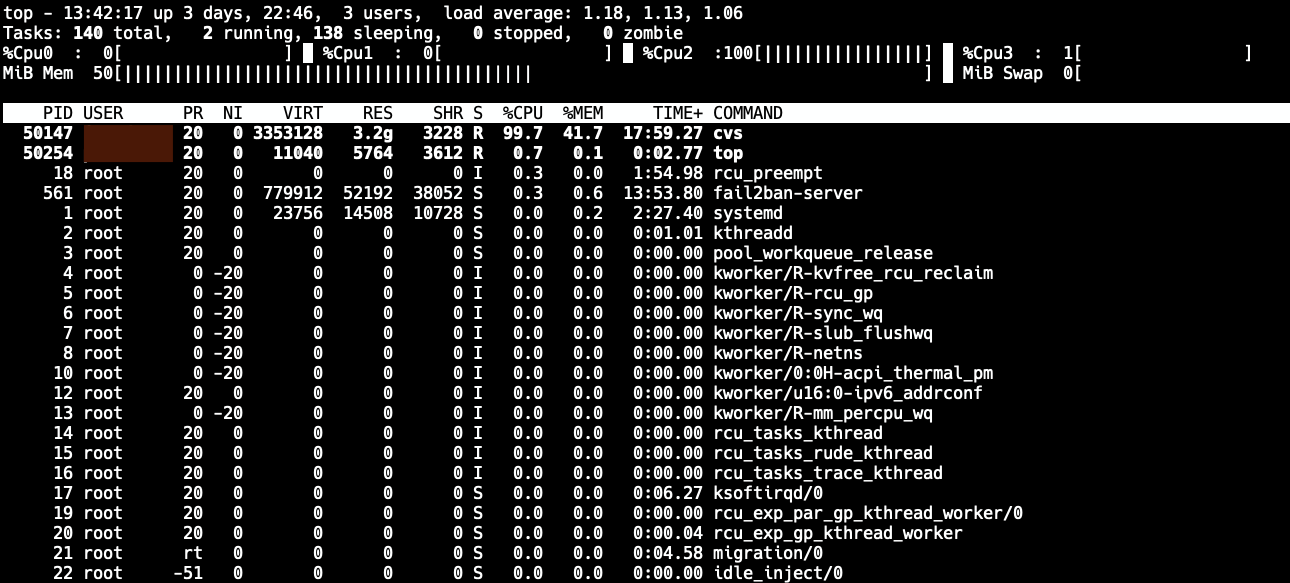
While working on our project, we occasionally have to do a full checkout of the whole codebase, which is several gigabytes. Over time, this operation has gotten very, very, very slow - I mean "2+ hours to perform a checkout" slow.
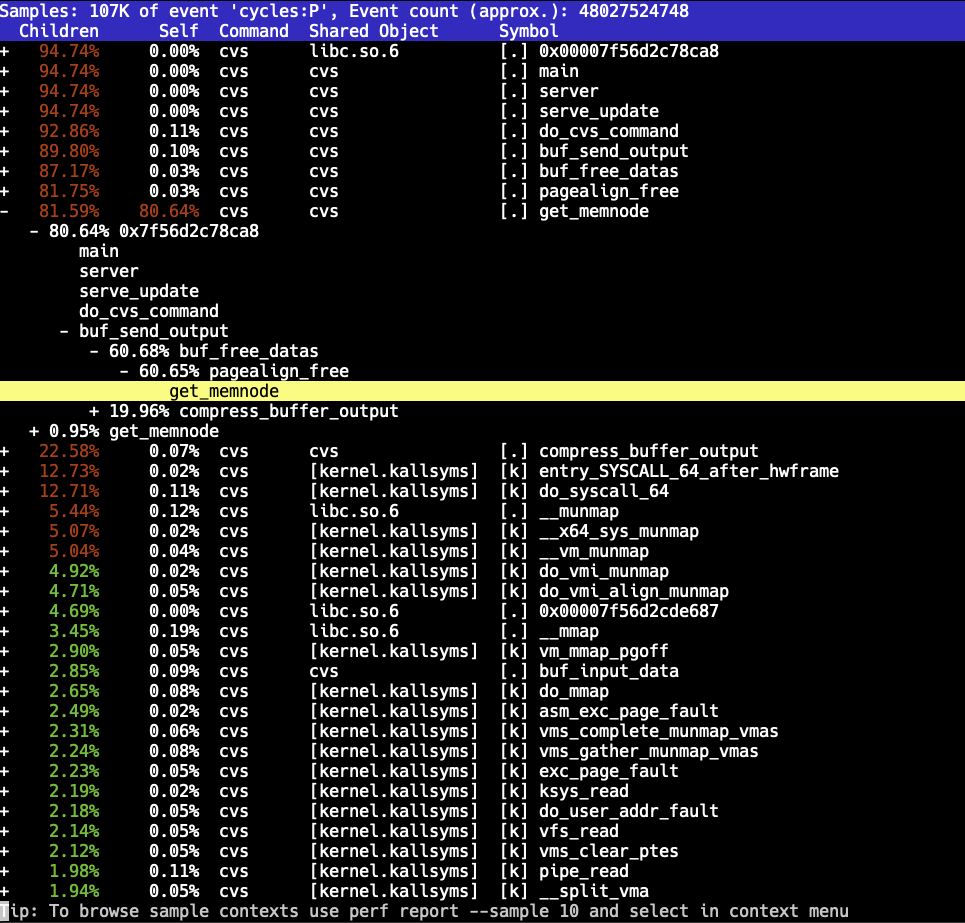
This was getting quite ridiculous. Even though it's CVS, it shouldn't crawl like this. A quick build of CVS with debug symbols and sampling the "cvs server" process with Linux perf showed something peculiar: The code was spending the majority of the time inside one function.
So what is this get_memnode() function? Turns out this is a support function from Gnulib that enables page-aligned memory allocations. (NOTE: I have no clue why CVS thinks doing page-aligned allocations is beneficial here - but here we are.)
The code in question has support for three different backend allocators:
1. mmap
2. posix_memalign
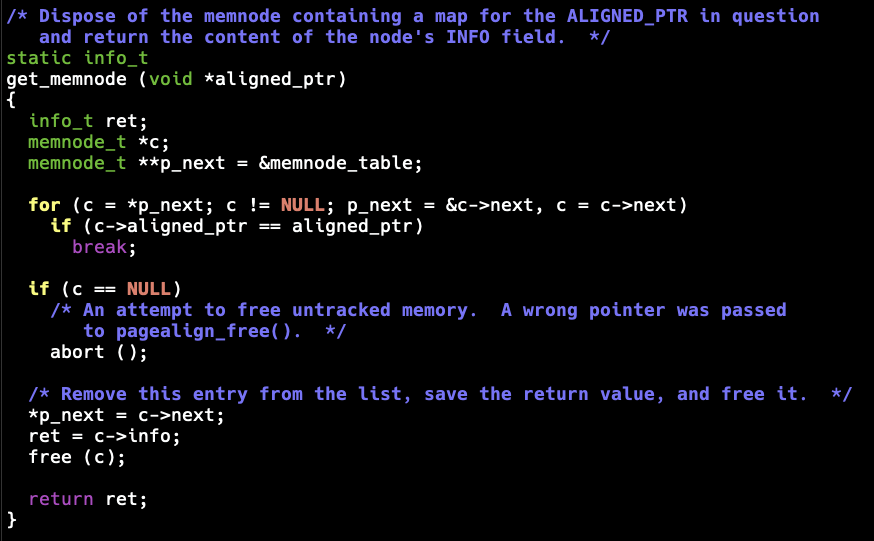
3. mallocSounds nice, except that both 1 and 3 use a linked list to track the allocations. The get_memnode() function is called when deallocating memory to find out the original pointer to pass to the backend deallocation function: The node search code appears as:
for (c = *p_next; c != NULL; p_next = &c->next, c = c->next)
if (c->aligned_ptr == aligned_ptr)
break;The get_memnode() function is called from pagealign_free():
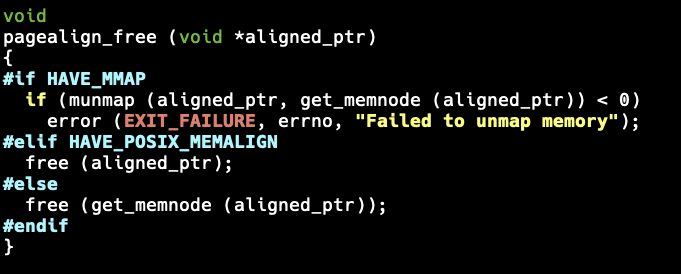
#if HAVE_MMAP
if (munmap (aligned_ptr, get_memnode (aligned_ptr)) < 0)
error (EXIT_FAILURE, errno, "Failed to unmap memory");
#elif HAVE_POSIX_MEMALIGN
free (aligned_ptr);
#else
free (get_memnode (aligned_ptr));
#endifThis is an O(n) operation. CVS must be allocating a huge number of small allocations, which will result in it spending most of the CPU time in get_memnode() trying to find the node to remove from the list.
Why should we care? This is "just CVS" after all. Well, Gnulib is used in a lot of projects, not just CVS. While pagealign_alloc() is likely not the most used functionality, it can still end up hurting performance in many places.
The obvious easy fix is to prefer the posix_memalign method over the other options (I quickly made this happen for my personal CVS build by adding tactical #undef HAVE_MMAP). Even better, the list code should be replaced with something more sensible. In fact, there is no need to store the original pointer in a list; a better solution is to allocate enough memory and store the pointer before the calculated aligned pointer. This way, the original pointer can be fetched from the negative offset of the pointer passed to pagealign_free(). This way, it will be O(1).
I tried to report this to the Gnulib project, but I have trouble reaching gnu.org services currently. I'll be sure to do that once things recover.
-
As it happens, we still use CVS in our operating system project (there are reasons for doing this, but migration to git would indeed make sense).
While working on our project, we occasionally have to do a full checkout of the whole codebase, which is several gigabytes. Over time, this operation has gotten very, very, very slow - I mean "2+ hours to perform a checkout" slow.
This was getting quite ridiculous. Even though it's CVS, it shouldn't crawl like this. A quick build of CVS with debug symbols and sampling the "cvs server" process with Linux perf showed something peculiar: The code was spending the majority of the time inside one function.
So what is this get_memnode() function? Turns out this is a support function from Gnulib that enables page-aligned memory allocations. (NOTE: I have no clue why CVS thinks doing page-aligned allocations is beneficial here - but here we are.)
The code in question has support for three different backend allocators:
1. mmap
2. posix_memalign
3. mallocSounds nice, except that both 1 and 3 use a linked list to track the allocations. The get_memnode() function is called when deallocating memory to find out the original pointer to pass to the backend deallocation function: The node search code appears as:
for (c = *p_next; c != NULL; p_next = &c->next, c = c->next)
if (c->aligned_ptr == aligned_ptr)
break;The get_memnode() function is called from pagealign_free():
#if HAVE_MMAP
if (munmap (aligned_ptr, get_memnode (aligned_ptr)) < 0)
error (EXIT_FAILURE, errno, "Failed to unmap memory");
#elif HAVE_POSIX_MEMALIGN
free (aligned_ptr);
#else
free (get_memnode (aligned_ptr));
#endifThis is an O(n) operation. CVS must be allocating a huge number of small allocations, which will result in it spending most of the CPU time in get_memnode() trying to find the node to remove from the list.
Why should we care? This is "just CVS" after all. Well, Gnulib is used in a lot of projects, not just CVS. While pagealign_alloc() is likely not the most used functionality, it can still end up hurting performance in many places.
The obvious easy fix is to prefer the posix_memalign method over the other options (I quickly made this happen for my personal CVS build by adding tactical #undef HAVE_MMAP). Even better, the list code should be replaced with something more sensible. In fact, there is no need to store the original pointer in a list; a better solution is to allocate enough memory and store the pointer before the calculated aligned pointer. This way, the original pointer can be fetched from the negative offset of the pointer passed to pagealign_free(). This way, it will be O(1).
I tried to report this to the Gnulib project, but I have trouble reaching gnu.org services currently. I'll be sure to do that once things recover.
So how does CVS use pagealign_xalloc? Like this:
/* Allocate more buffer_data structures. */
/* Get a new buffer_data structure. */
static struct buffer_data *
get_buffer_data (void)
{
struct buffer_data *ret;ret = xmalloc (sizeof (struct buffer_data));
ret->text = pagealign_xalloc (BUFFER_DATA_SIZE);return ret;
}Surely BUFFER_DATA_SIZE will be something sensible? Unfortunately it is not:
#define BUFFER_DATA_SIZE getpagesize ()
So it will by create total_data_size / pagesize number of list nodes in the linear list. Maybe it's not that bad if the nodes are released in an optimal order?
The pagealign code stores new nodes always to the head of its list:
new_node->next = memnode_table;
memnode_table = new_node;The datanodes in CVS code are however inserted into a list tail:
newdata = get_buffer_data ();
if (newdata == NULL)
{
(*buf->memory_error) (buf);
return;
}if (buf->data == NULL)
buf->data = newdata;
else
buf->last->next = newdata;
newdata->next = NULL;
buf->last = newdata;This creates a pathological situation where the nodes in the aligned list are in worst possible order as buf_free_datas() walks the internal list in first to last node, calling the pagealign_free:
static inline void
buf_free_datas (struct buffer_data *first, struct buffer_data *last)
{
struct buffer_data *b, *n, *p;
b = first;
do
{
p = b;
n = b->next;
pagealign_free (b->text);
free (b);
b = n;
} while (p != last);
}In short: This is very bad. It will be slow as heck as soon as large amounts of data is processed by this code.
-
R AodeRelay shared this topic
-
So how does CVS use pagealign_xalloc? Like this:
/* Allocate more buffer_data structures. */
/* Get a new buffer_data structure. */
static struct buffer_data *
get_buffer_data (void)
{
struct buffer_data *ret;ret = xmalloc (sizeof (struct buffer_data));
ret->text = pagealign_xalloc (BUFFER_DATA_SIZE);return ret;
}Surely BUFFER_DATA_SIZE will be something sensible? Unfortunately it is not:
#define BUFFER_DATA_SIZE getpagesize ()
So it will by create total_data_size / pagesize number of list nodes in the linear list. Maybe it's not that bad if the nodes are released in an optimal order?
The pagealign code stores new nodes always to the head of its list:
new_node->next = memnode_table;
memnode_table = new_node;The datanodes in CVS code are however inserted into a list tail:
newdata = get_buffer_data ();
if (newdata == NULL)
{
(*buf->memory_error) (buf);
return;
}if (buf->data == NULL)
buf->data = newdata;
else
buf->last->next = newdata;
newdata->next = NULL;
buf->last = newdata;This creates a pathological situation where the nodes in the aligned list are in worst possible order as buf_free_datas() walks the internal list in first to last node, calling the pagealign_free:
static inline void
buf_free_datas (struct buffer_data *first, struct buffer_data *last)
{
struct buffer_data *b, *n, *p;
b = first;
do
{
p = b;
n = b->next;
pagealign_free (b->text);
free (b);
b = n;
} while (p != last);
}In short: This is very bad. It will be slow as heck as soon as large amounts of data is processed by this code.
So, has CVS always been this broken?
It doesn't look like it. At least some versions of CVS use far more sensible code: https://github.com/openbsd/src/blob/56696e8786be09c79aaaadb09d99b103c314f835/gnu/usr.bin/cvs/src/buffer.c#L92
This code doesn't suffer from the "two lists" syndrome, so it remains fast no matter what. It allocates 16 pages at a time. It never frees the memory and just keeps it in a list to be reused when the need arises.